

SPECTRUM: Natūralios kalbos analizė: nuo tekstinių duomenų rūšiavimo iki netikrų tekstų generavimo
Skaitmeninis natūralios kalbos apdorojimas suprantamas kaip teksto analizės, informatikos ir dirbtinio intelekto sričių mišinys, susijęs su kompiuterių ir žmonėms suprantamos kalbos sąveika. Kitaip tariant, tai yra metodai, padedantys apdoroti ir analizuoti natūralios kalbos tekstus, esančius skaitmeniniu formatu. Šios srities tikslas – įgalinti „suprasti“ dokumentų turinį – semantinę informaciją, įskaitant juose slypinčius kontekstinius kalbos niuansus. Tam yra kuriami matematiniai modeliai, kurie gali išgauti dokumentuose esančią informaciją, ją sujungti, apibendrinti ir pratęsti, pateikti įžvalgas, klasifikuoti ar klasterizuoti dokumentus.
Automatizuotas teksto vertimas
Natūralios kalbos analizė nėra nauja tyrimų sritis. Nuo pat kompiuterių sukūrimo XX a. 6-ajame dešimtmetyje dėl didelės apimties tekstų kiekio ir greito jų vertimo skaitmeninėmis priemonėmis tapo aktualūs tekstų vertimo uždaviniai. Pirmieji skaitmeniniai kalbos vertimo uždaviniai pasižymėjo tekstų ir frazių žodynų sąrašais ir tiesiogine jų paieška žodynuose. Šių sprendimų problema – bet koks žodis, kuriame yra korektūros klaida ar kurio nėra žodyne, nebus išverstas. Tobulėjant skaičiavimo technikai 9-ajame dešimtmetyje išplėtoti statistiniai vertimo modeliai, grįsti bajesiniais modeliais ir kalbos žodžių apriorinėmis tikimybėmis. Modeliai atsižvelgdavo į sakinyje jau esančius žodžius ir galėdavo parinkti labiausiai tikėtiną verčiamą žodį. Žinoma, statistinis kalbos vertimas yra šabloniškesnis, todėl versti grožinę literatūrą su pasiūlytais posakiais būdavo sunkiau nei tipinius formalius dokumentus. Statistinis vertimas pamažu tobulėjo ir nuo 10-ojo dešimtmečio skaitmenizacija suteikė galimybę rinkti tekstynus ir kurti modelius, kurie nėra grįsti vien pažodiniu vertimu. Lingvistinių taisyklių ir algoritmų sudarymas leido struktūrizuoti vertimus ir šios technologijos buvo taikomos iki kalbos modelių, kuriamų giliaisiais neuroniniais tinklais, atsiradimo.
Proveržis taikant neuroninius tinklus
Gilieji neuroniniai tinklai – tai matematinis modelis, leidžiantis apdoroti sudėtingos struktūros duomenis, pavyzdžiui, tekstą. Jų proveržis įvyko apie 2014 m., atsiradus dideliems kiekiams atvirų duomenų rinkinių (tekstynų), specializuotai skaičiavimo technikai ir naujiems dirbtinių neuroninių tinklų modeliams, be to, tapus prieinamai programinei įrangai, atliekančiai automatinį modelių nežinomų parametrų vertinimą. Taip kilo nauja skaitmeninė revoliucija. Visi šiandien aptinkami išmanūs duomenų analize grįsti algoritmai buvo išplėtoti po minėtų technologijų sinergijos. Elono Musko įkurtos dirbtinio intelekto tyrimų organizacijos „OpenAI“ tyrėjai neseniai paskelbė studiją, kurioje teigiama, kad giliaisiais neuroniniais tinklais kuriamų geriausių modelių dydžiai ir skaičiavimo resursai, reikalingi tokiems modeliams sukurti, dvigubėja kas 3,5 mėnesio. Proveržį skatina būtent šių modelių sėkmė apdorojant kompleksinės struktūros duomenis. Natūralios kalbos uždavinių kontekste pradėti kurti nauji kalbos modeliai, kurie atvėrė naujas galimybes natūralios kalbos ir tekstų analizės uždaviniuose. Didžiausią postūmį davė 2018 m. pasiūlytas BERT kalbos modelis.
Kalbos modeliai koduoja tekstą į skaičių eilutę
Kalbos modelis yra toks matematinis modelis, kuris užkoduoja tam tikrą tekstą į skaitinę reprezentaciją – skaičių eilutę, turinčią užkoduotą semantinę ir kontekstinę informaciją. Tai vadinama aukšto lygio požymių vektoriumi. Įprastai mašininio mokymo uždaviniuose konstruojamas modelis prognozuoti žinomas charakteristikas. Pavyzdžiui, sporto skilties naujieną automatiškai klasifikuoti kaip sporto klasę galime turėdami istorinę informaciją, kokios naujienos skelbiamos sporto skiltyje. Vis dėlto duomenų charakteristikų arba žymenų turėjimas yra daug kainuojantis procesas. Didžiosios įmonės dažnai samdo duomenų žymėjimo darbuotojus rinkti duomenis apie norimą informaciją, pavyzdžiui, sužymėti, ar pasisakymas apie finansines naujienas buvo teigiamas, ar neutralus, ar neigiamas. Tačiau turint milžiniškus tekstynus duomenų žymėjimas yra neįgyvendinamas praktiškai. Pagrindinė inovacija, pasiūlyta kuriant kalbos modelius – tai egzistuojančių duomenų panaudojimas nesprendžiant konkretaus uždavinio. Imamas bet koks tekstas ir prognozuojama, koks žodis galėtų būti atsitiktinėje vietoje praleidus jį.
Kitas automatizuotas duomenų panaudojimo būdas – prognozuoti, ar du iš eilės einantys sakiniai yra nuoseklūs, t. y. ar tvarka yra nuosekli, ar ne. Sprendžiant tokio tipo uždavinius, sukuriamas kalbos modelis, gebantis užkoduoti visą reikalingą informaciją iš aukšto lygio reprezentacijų. Naudojant aukšto lygio reprezentacijas atsiranda visiškai nauja terpė tekstiniams duomenims analizuoti. Pavyzdžiui, pasirinkus ir fiksavus matą, galima apskaičiuoti skaitinį dviejų tekstų panašumą, klasifikuoti tekstą ar spręsti kitus natūralios kalbos uždavinius (1 pav.).
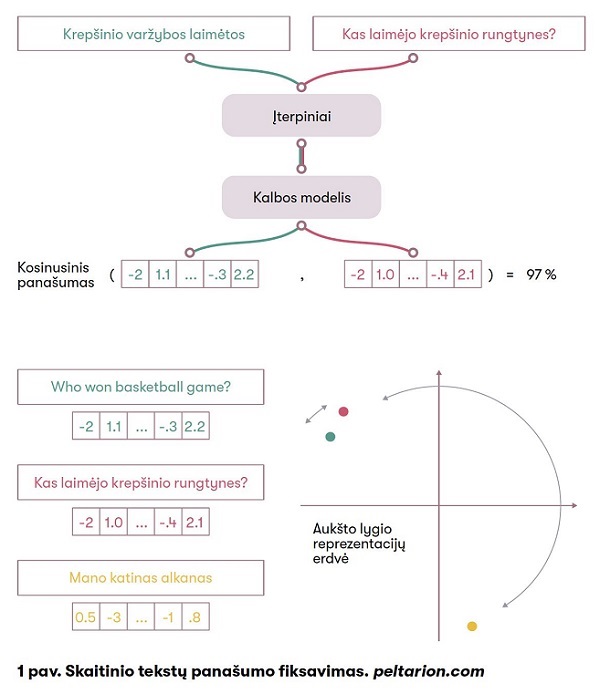
Pasiūlytas modelis rėmėsi nauja dėmesio sutelkimo transformacija, kuri leido sujungti vidinius sąryšius tarp teksto žodžių ir taip užkoduoti tik reikšmingą informaciją, kuri yra tekste (2 pav.).
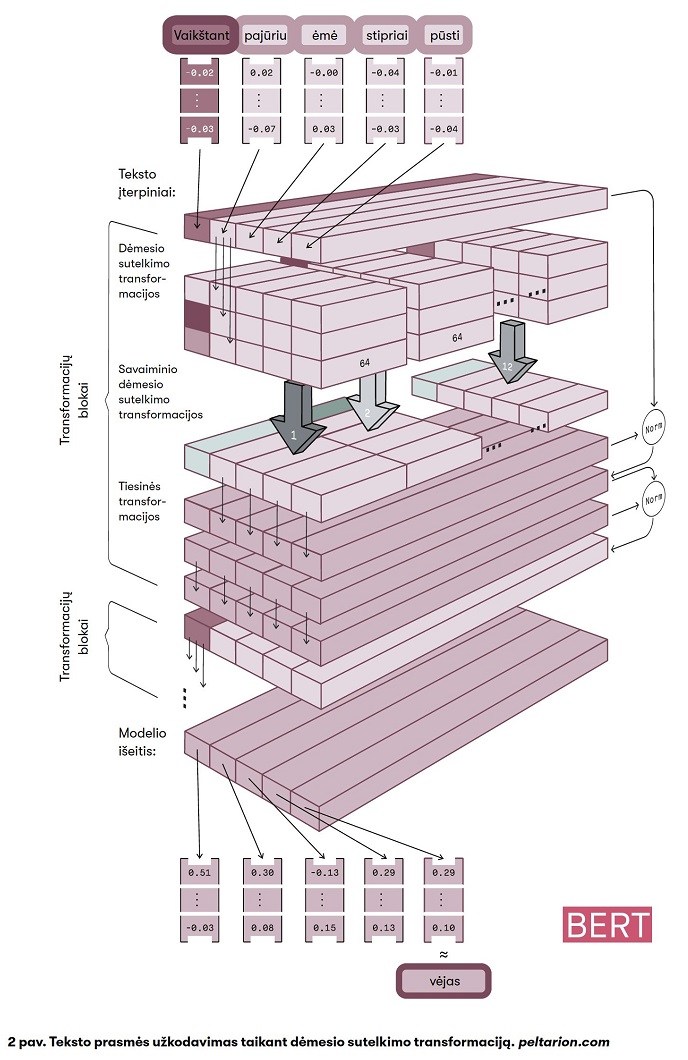
Taikymai natūralios kalbos apdorojimo uždaviniuose
Kalbos modeliai dar suprantami kaip didelė kodavimo sistema, gebanti užkoduoti tekstą simboliniu formatu į aukšto lygio reprezentaciją, kuri leidžia spręsti įvairiausius teksto analizės uždavinius. Štai keletas kalbos modelių panaudojimo atvejų:
● Teksto klasifikavimas – tipinis kalbos modelių taikymo pavyzdys. Tai gali būti vertinimų klasifikavimas (teigiama / neutrali / neigiama naujiena), laiškų klasifikavimas (tiesioginiai laiškai / socialinė medija / prenumeratos / šlamštas) ir pan. Visa tai įmanoma padaryti teksto pastraipas pavaizdavus kaip fiksuoto dydžio aukšto lygio požymius, kurie neša visą semantinę informaciją apie tai, kas yra tekste. Tokie paprasti uždaviniai vėliau labai sėkmingai taikomi praktikoje. Pavyzdžiui, palikti komentarai ar atsiliepimai, kurie reprezentuoti tekstine išraiška, nesunkiai gali būti suklasifikuoti pagal komentaro turinį.
● Klausimų ir atsakymų modeliai – tai matematinių modelių klasė, kuri prognozuoja, kur tam tikroje pastraipoje yra užduoto klausimo atsakymas. Tokio tipo uždaviniai formuluojami kaip atsakymo pradžios ir pabaigos pozicijos klasifikavimo uždaviniai. Visiškai panašiai yra kuriami ir klausimų bei atsakymų modeliai be papildomos informacijos. Tokio tipo modeliai yra realizuojami pokalbių robotų sistemose.
● Teksto santraukų matematiniai modeliai grindžiami dėmesio sutelkimo transformacijos principu. Teksto informacija užkoduojama į aukšto lygio požymius ir tai leidžia turėti ją visą mažos dimensijos reprezentacijoje. Tuomet duomenų dekoderis sugeneruoja trumpą tekstą, atitinkantį semantinę ir kontekstinę informaciją, užkoduotą požymių vektoriuje.
● Autorystės nustatymas – tai tekstų klasifikavimas pagal autorių. Kiekvienas iš mūsų turime unikalų mąstymą ir pasaulio sampratą. Todėl ir rašydami tekstą skaitmeninėje erdvėje paliekame savo biometrinį žymenį. Kalbos modeliai, skirti klasifikuoti tekstus pagal autorius, užkoduoja informaciją apie teksto rašymo stilių, minčių dėstymo šabloniškumą. O aukšto lygio reprezentacijos leidžia atlikti paiešką. Kiekvienas, parašęs komentarą, pasisakymą ar tekstą, gali suskaičiuoti panašumo su kiekvienu kitu norimu tekstu mato reikšmę. Visiškai kaip biometrinio identifikavimo atveju vyksta paieška pagal teksto rašymo stilių.
● Teksto klaidų identifikavimas yra labai išplėtota natūralios kalbos modelių dalis. Turint aibę tekstų – tekstyną, galima sukurti tokio tipo tekstų reprezentacijas. Kiekvienas netipinis tekstas, žodžiai su korektūros klaidomis suformuoja kitokį nei įprasta požymių šabloną. Šablonų lyginimas ir atitiktis tipiniams šablonams veda prie netipinių „išskirčių“, dar žinomų kaip klaidos, identifikavimo.
● Teksto generavimas per pastaruosius kelerius metus tapo žinomiausiu natūralios kalbos modelių taikymo objektu. Šis kalbos modelis leidžia turėti visą reikalingą informaciją apie kalbą, tipinius jos vartojimo būdus, semantinę ir kontekstinę informaciją. Dėl to formuluodami uždavinį, leidžiantį prognozuoti žodžius sakinyje, mes pereiname prie visiškai dirbtinio teksto generavimo.
Dirbtinis tekstas sunkiai atskiriamas nuo tikro
Praėjusiais metais organizacija „OpenAI“ sukūrė modelį, kuris gali pratęsti pradėtą sakinį, nes informaciją gauna iš paruošto 400 mlrd. žodžių tekstyno. Vienas mygtuko paspaudimas, ir sistema gali sugeneruoti netikrą tekstą, kurio neatskirsi nuo tikro, jei nepradėsi jo atidžiai skaityti. Netikro teksto kombinacija su teksto palyginimo funkcionalumu dar labiau praplečia taikymo galimybes. Tampa pavojingi taikymai dezinformacijos tikslais, kai sugeneruojama daug netikrų tekstų ir iš jų pasirenkamas pats panašiausias į norimą tikrą tekstą, pvz., kokio nors politiko pasisakymas.
Šios netikrų tekstų problemos ypač aktualios dabar, kai mes visi smarkiai įsitraukėme į socialinių tinklų gyvenimą, o jų turinio kūrėjai mus ten nori išlaikyti kuo ilgiau. Šis siekis lengviausiai įgyvendinamas mums rodant personalizuotą informaciją, kurios kažkada ieškojome, kuria domėjomės. Čia ir iškyla problema – jei kiekvienas turintis mobilųjį įrenginį gauna personalizuotą informacijos srautą, kuris vis plečiasi, jame pasidaro dar lengviau paslėpti melagienas ir netikrus sugeneruotus tekstus.
Žinoma, piktybiškas teksto generavimas yra tik vienas iš technologijos taikymo pavyzdžių. Esama ir labai sėkmingų praktiškų taikymų. Turbūt kiekvienas iš mūsų kasdienėje veikloje susidūrėme su teksto užbaigimo (tęsinių pasiūlymo) funkcija. Tai natūralios kalbos modelių taikymo pavyzdys.
O technologinio proveržio pavyzdys galėtų būti projektas „Github Copilot“, kai tyrėjų komanda iš organizacijos „OpenAI“ sukūrė kalbos modelį, skirtą generuoti programinio kodo užbaigimą vien iš parašyto metodo pavadinimo ar metodo kodo pradžios. Žinoma, tai skamba labai egzotiškai, tačiau duomenų analizės požiūriu tai neatrodo utopiškai. Vienas didžiausių atviros prieigos projektų šaltinių „Github“, apimantis per 190 milijonų projektų, yra didžiausias tokio tipo duomenų šaltinis pasaulyje. Inovatyvus sprendimas, tapęs realia ir praktiška pagalba programuotojui, buvo sugeneruoto modelio panaudojimas realiomis sąlygomis. Jei modelio sugeneruotas metodas panaudojamas, modelis gauna sėkmingo panaudojimo signalą ir sukuria dar geresnį programinės kalbos modelį.
Kalbos modelis prognozuoja būsimas profesijas
Kalbant apie natūralios kalbos modelių kūrimą Lietuvoje, galima paminėti neseniai Vilniaus universiteto Matematikos ir informatikos fakulteto mokslininkų komandos sukurtą kalbos modelį, kuris leidžia prognozuoti, kokia bus aukštųjų ir profesinių mokyklų absolventų profesija, atsižvelgiant į tai, koks yra jų pasirinktos studijų programos aprašas. Sukurtas kalbos modelis leidžia ne tik pamatyti, kokia bus labiausiai tikėtina (sub)profesija pasirinkus tam tikrą studijų programą, bet ir modeliuoti, kas nutiktų, jei asmuo baigtų papildomas kito profilio studijas. Dar įdomesni eksperimentai leidžia keisti studijų programos aprašą, pavyzdžiui, pridėti naujų dalykų / kompetencijų ir pasižiūrėti, kaip tuomet keistųsi absolvento profesija.
Įdomiausias dalykas tyrinėjant kuriamus natūralios kalbos modelius – jų galimybės agreguoti ir struktūrizuoti informaciją. Pradiniai kalbos modeliai buvo orientuoti į konkrečias sritis, pavyzdžiui, modelis BioBERT – taikyti biomokslų srities teksto užkodavimą į aukšto lygio požymius, o pastaruoju metu sukurti modeliai sudaro galimybes kurti daugiakalbius ir daugelio sričių kalbos modelius. Tokio tipo modeliai leidžia sėkmingai užkoduoti tiek skirtingų kalbų informaciją, tiek recepto aprašymą ar mokslinį rezultatą. Vėliau toks kalbos modelis gali būti taikomas bet kokiems kalbos apdorojimo uždaviniams kurti ar spręsti.
Dr. Linas Petkevičius
Vilniaus universiteto
Matematikos ir informatikos fakultetas
2021-10-15